在 Jupyterlab 中使用 Pandas
pip install jupyterlab
如果是在 WSL2 系统中使用 Jupyterlab,需要如下配置才能默认使用 Windows 主机上的浏览器打开界面
禁用 use_redirect_file
jupyter lab --generate-config
vim ~/.jupyter/jupyter_lab_config.py
c.ServerApp.use_redirect_file = False
使用环境变量 BROWSER 指定 Windows 主机浏览器路径
export BROWSER="/mnt/c/Program Files/Mozilla Firefox/firefox.exe"
使用 localhost 作为 WSL 系统主机名
vim /etc/wsl.conf
[network]
hostname = localhost
启动 jupyterlab,指定 IP 和端口,否则可能报错
jupyter lab --ip=0.0.0.0 --port 8080
导入 Pandas
import pandas as pd
import numpy as np
print(pd.__version__)
print(np.__version__)
数据结构
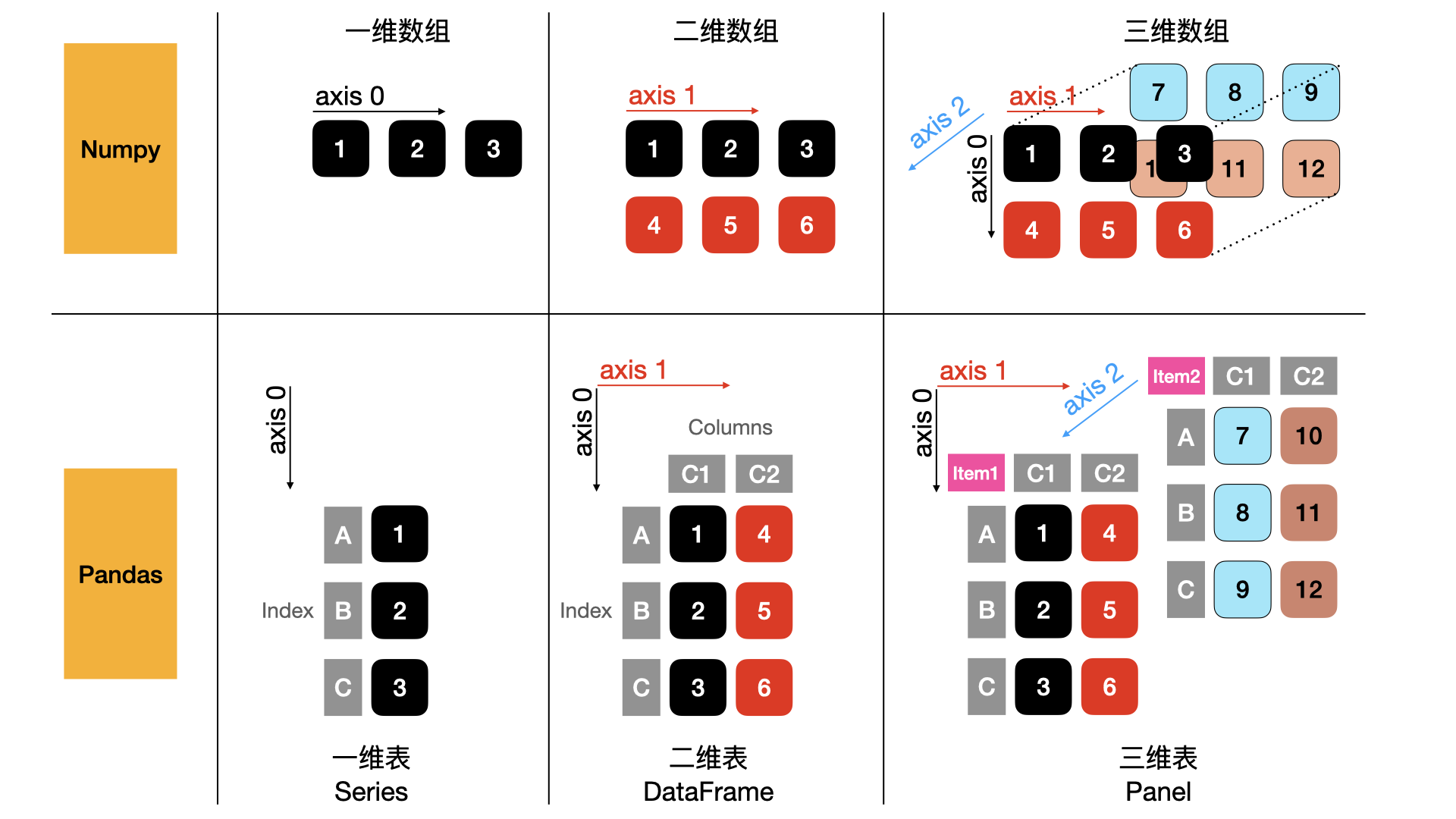
数据操纵
df = pd.read_csv('file.csv')
df.shape
查看 DataFrame 单列数据
将列名字符串直接传递给 DataFrame,返回类型 Series
df.A
df['A']
查看 DataFrame 多列数据
将列名作为一个 list 传递给 DataFrame,返回类型 DataFrame
df[['A', 'B', 'C']]
查看指定行和列的数据
help(pd.DataFrame.iloc)
传入一个标量值 0,返回第一行,类型 Series
df.iloc[0]
传入一个列表 [0],返回第一行,类型 DataFrame
df.iloc[[0]]
传入两个标量,返回第一行,第一列,类型 Scalar
df.iloc[0, 0]
传入两个列表,返回第一行和第三行,第二列和第四列,类型 DataFrame
df.iloc[[0, 2], [1, 3]]
时间比较
df[df.datetime <= '2022-01-01T00:00:00.000Z']
两表合并
help(pd.merge)
pd.merge(dfA,
dfB,
left_on='ColumnA',
right_on='ColumnB',
how='inner',
suffixes=('_A', None))
按组统计
grouped = df.groupby(['datetime', 'os_family'])
grouped[['id']].agg('count')
格式化打印 json
import json
print(
json.dumps(
json.loads(df.json.iloc[0]),
indent=2
)
)
从字符串提取时间并添加为一列
df['datetime']=df.json.str.extract(r'(\d{4}-\d{2}-\d{2}T\d{2}:\d{2}:\d{2}\.\d{3}Z)')
集合过滤
isin() 函数
help(pd.Series.isin)
help(pd.DataFrame.isin)
dfA.id 不在 dfB.id 中的数据
dfA[~dfA.id.isin(dfB.id)]
表合并过滤
pd.merge(dfA, dfB, on='id', how='inner', suffixes=('_A', '_B'))
多条件过滤
# 并
df[(df.operation == 'create') & (~df.json.str.contains('Mario'))]
# 或
df[(df.datetime > '2022-01-01T00:00:00.000Z') | df.datetime.isna()]
集合排序
df.sort_values(by='datatime')
help(pd.DataFrame.sort_values)