概念解释
-
假设函数(Hypothesis Function): 用来拟合数据集,有线性函数和非线性函数。
-
正向传播(Forward Propagation): 用来计算假设函数的输出值 $h_\theta(x)$(即 $\hat{y}$)。
-
代价函数(Cost Function): 用来检验假设函数的输出值 $\hat{y}$ 与真实值 $y$ 之间的误差大小。
-
反向传播(Backpropagation): 用来计算代价函数 $J(\theta)$ 关于参数 $\theta$ 的偏导数 $\dfrac{\partial}{\partial \theta}J(\theta)$。
-
优化算法(Optimization Method): 使用参数 $\theta$ 最小化代价函数 $J(\theta)$。
设计模型结构
-
输入单元的数量 = 特征 $x^{(i)}$ 的维度。
-
输出单元的数量 = 分类的个数。
-
隐藏层单元数量 = 通常越多越好,但太多会导致运算量过大。
-
隐藏层数量 = 默认为一个隐藏层,如果设计多个隐藏层,建议隐藏层单元数量相同。
训练神经网络
-
随机初始化权重(即参数 $\theta$)。
Theta = rand(10, 11) * (2*INIT_EPSILON) - INIT_EPSILON; -
实现正向传播得到任意输入 $x^{(i)}$ 的 $h_\theta(x^{(i)})$。
-
实现代价函数。
-
实现反向传播来计算偏导数。
-
用梯度检查(gradient checking)来确定反向传播计算正确,然后在代码中禁掉梯度检查。
\[gradApprox = \dfrac{(J(\theta+\epsilon) - J(\theta-\epsilon))}{(2\epsilon)}\] -
用梯度下降(gradient descent)或内建的优化函数,使用权重($\theta$)来最小化代价函数。
模型评估
Bias vs. variance
高偏差(high bias): 欠拟合(underfitting),$J_{train}(\Theta)$ 和 $J_{CV}(\Theta)$ 都很高,并且 $J_{train}(\Theta) \approx J_{CV}(\Theta)$。
高方差(high variance): 过拟合(overfitting), $J_{train}(\Theta)$ 很低,但是 $J_{CV}(\Theta)$ 要比 $J{train}(\Theta)$ 高很多。
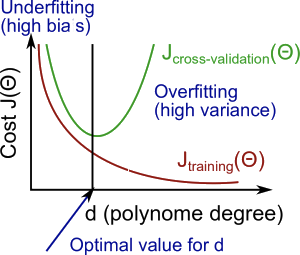
学习曲线(learning curve)
只有少量训练样本时(例如1个,2个或3个),很容易得到0误差,因为总可以找到一个二次曲线能够通过每个样本点。因此:
- 随着样本规模变大,二次函数的误差值会增加
- 当样本数量达到m个或一定规模时,误差值会逐渐稳定
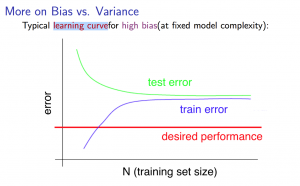
高偏差(high bias):
较小的训练集: $J_{train}(\Theta)$ 会比较低而 $J_{CV}(\Theta)$ 会比较高。
较大的训练集: $J_{train}(\Theta)$ 和 $J_{CV}(\Theta)$ 都会很高,并且 $J_{train}(\Theta) \approx J_{CV}(\Theta)$。
如果遇到高偏差(high bias)的情况,增加更多训练数据没有什么帮助。
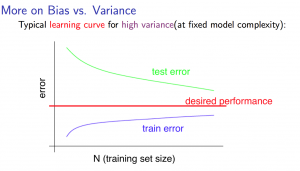
高方差(high variance)
较小的训练集: $J_{train}(\Theta)$ 会比较低而 $J_{CV}(\Theta)$ 会比较高。
较大的训练集: $J_{train}(\Theta)$ 随着训练集规模变大而增加而 $J_{CV}(\Theta)$ 会持续下降,并且 $J_{train}(\Theta) \lt J_{CV}(\Theta)$,但二者之间的差距仍然非常大。
如果遇到高方差(high variance)的情况,增加更多训练数据会有帮助。
处理数据倾斜(handle skewed data)
Error Metrics for Skewed Class
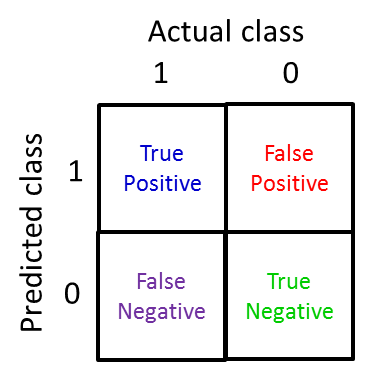
准确率(Accuracy)
\[\text{Accuracy} = \dfrac{\text{Number of correct predictions}}{\text{Total number of preditcions}} = \dfrac{\text{TP+TN}}{\text{TP+TN+FP+FN}}\]精确率(Precision)
\[\text{Precision} = \dfrac{\text{True Positives}}{\text{Number of predict as positive}} = \dfrac{\text{True Positives}}{\text{True Positives + False Positives}}\]召回率(Recall)
\[\text{Recall} = \dfrac{\text{True Positives}}{\text{Number of actual positive}} = \dfrac{\text{True Positives}}{\text{True Positives + False Negatives}}\]
| 真正例(True Positives): 8 | 假正例(False Positives): 2 |
|---|---|
| 假负例(False Negatives): 3 | 真负例(True Negatives): 13 |
 提高分类阈值,假正例减少,精确率提高,同时假负例增多,召回率降低。
提高分类阈值,假正例减少,精确率提高,同时假负例增多,召回率降低。
 降低分类阈值,假正例增加,精确率降低,同时假负例减少,召回率提高。
降低分类阈值,假正例增加,精确率降低,同时假负例减少,召回率提高。
$\boldsymbol F_1$ score
\[F_1 = 2\dfrac{P \cdot R}{P+R}\]